- Published on
OCRFeeder 0.8.1
- Authors

- Name
- Joaquim Rocha
- Principal Software Engineering Manager at Microsoft
Taking advantage of the holidays, I have been dedicating some time to my side projects so today I am giving you OCRFeeder version 0.8.1!
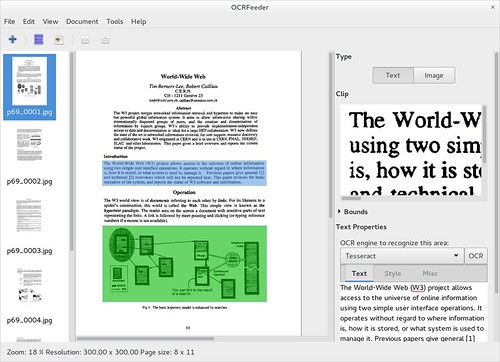
The last OCRFeeder version had a very important change which was the port to GObject introspection and I was already expecting a few bugs to pop up here and there. That proved to be true and so this version is mainly about bug fixing. Specifically there was an issue related to GDK’s threads which caused the application to abort. Besides that, exporting a document or saving/loading a project was not working correctly due to unicode issues (because Python is very nice but working with unicode is sometimes more annoying than it should be, at least in versions prior to Python 3). Anyway, all that should be working correctly now!
Besides squashing bugs, I also made some long due changes: made the Preferences dialog smaller (by adding its contents to a scrolled window) and migrated the application and engines’ settings to the XDG user configuration folder as opposed to .ocrfeeder. Yes, I know that I should be using GSettings for the application’s settings by now but there were more critical changes to be done. Besides a small change in the widgets that set a box’s type (from a radio button style to a non-indicator, grouped pair of buttons), there are no other UI changes but I really like how much more polished OCRFeeder seems with the nice recent GTK+ styles.
Future
I have a number of ideas to make the application better not only in terms of UI/UX but also in terms of features. The detection algorithm hasn’t been touched for years and I am sure it can be improved not only in terms of performance but also in terms of accuracy. One cool feature I’d love to see implemented is to have a quick way of translating a document’s contents. This would be helpful e.g. to users living abroad who might need to translate letters to a language they speak. Nonetheless, as mentioned in my previous post about OCRFeeder, it is indeed not easy to find the time and motivation to dedicate to the project these days with all the work, life and other side projects so I don’t know when I will have time for it again. In that regard, if you want to give me a hand, you’d make me very happy as there is a lot of work to be done.
Happy holidays everyone!