- Published at
OCRFeeder version 0.7.10
- Authors
-
-

- Name
- Joaquim Rocha
-
The previous OCRFeeder‘s version was released in April. I have been busy with Skeltrack and other projects but, between my personal time and Igalia‘s precious hackfest time, here we have a new version of the best Free Software OCR application.
For this 0.7.10 version I have improved the way that the document generators (the classes that generate the desired exportation formats) are used inside OCRFeeder. I have abstracted their use making it easy to add new document generators in the future. The command line version, which has been limited to generating only the original exportation formats (ODT and HTML), also benefits from these changes; from this version on, it is possible to generate documents with any of the existing exportation format from the command line. For example, to generate a plain text file:
$ ocrfeeder-cli -i scan1.ppm -i scan2.jpeg -f TXT -o text_doc.txt
The current PDF exportation still has flaws that will take some time to fix but for now I have fixed a big issue: line wrap. The text lines would not wrap when written in the PDF document and so, long lines would go beyond the pages’ limits. This should be improved with this new version and I hope I have the time in the future to fix the other issues.
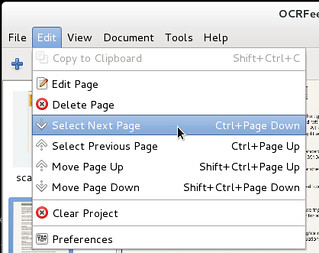
Moving (or swapping) pages by dragging them seems to have stopped working. This seems like a PyGTK bug but anyway it was the necessary excuse to implement actions for selecting and moving the pages using the menu or shortcuts. This will make the mentioned bug less important and also offers the possibility of moving pages easily to visually impaired users.
Future
I want to fix some issues in OCRFeeder’s architecture, especially in what comes to the UI part. This should probably be done together with a port the amazing GObject’s Introspection. Jan Losinski, from TU Dresden, was kind enough to send me some patches that make the OCRFeeder’s recognition parallel. This feature needs to be polished but it will likely land in the next version of OCRFeeder. Last but not least, I need to check how to make it easy to integrate the user’s language in the OCR recognition. I exchanged some emails with the people from AltLinux distro who seem to have already implemented this in their repositories but I need time to try and review their patches.
Contribute
If you want to contribute and make this project better, fear not! The code is all Python and I’m available to help you get started so email me if you’re interested.
Enjoy OCRFeeder 0.7.10!